 | Plan 9 от Bell Labs |  |
| Главная страница Программы Гостевая книга | |||||||
| |||||||
Rob Pike
Dave Presotto
Sean Dorward
Bob Flandrena
Ken Thompson
Howard Trickey
Phil Winterbottom
Bell Laboratories, Murray Hill, NJ, 07974 USA
Мотивация
ПРИМЕЧАНИЕ: Было опубликовано немного в иной форме в Computing Systems, Vol 8 #3, лето 1995, с. 221–254.
К середине 1980-х тенденции в вычислительной технике отошли от больших централизованных компьютеров, работающих в режиме разделения времени к сетям из меньших персональных машин, обычно рабочих станций UNIX. Люди устали от перегруженных бюрократичных машин разделения времени и горели желанием перейти на небольшие, самообслуживающиеся системы, даже если бы это означало убыток в ресурсах. Так как микрокомпьютеры стали быстрее, убыток был восстановлен, и этот стиль работы остается популярным сегодня.
В спешке перехода на персональные рабочие станции некоторые их слабости, однако, были проигнорированы. Первая из них в том, что операционная система, под управлением которой они работают: UNIX – самая старая система разделения времени и имеет проблемы с приспособлением к идеям, родившимся после нее. Графика и работа с сетью были добавлены к UNIX уже во время ее существования и остаются слабо интегрированными и трудно администрируемыми. Более важным является то, что раннее сосредоточение на обладании личными машинами создало трудности для того, чтобы сети машин служили в качестве старых монолитных систем разделения времени. Разделение времени централизовывало управление и амортизацию издержек и ресурсов; персональная вычислительная техника сломала, демократизировала и, в конце концов, усилила административные проблемы. Выбор старой операционной системы разделения времени для работы на этих персональных машинах, сделал сложным гладкое связывание систем друг с другом.
Plan 9 зарождался в конце 1980-х как попытка решить обе эти проблемы: сформировать систему, централизованно администрируемую и экономически выгодно использующую дешевые современные микрокомпьютеры как вычислительные элементы. Идея в том, чтобы сформировать систему разделения времени из рабочих станций, но новым способом. Различные компьютеры должны оперировать различными задачами: небольшие, дешевые машины в офисах должны послужить в качестве терминалов, обеспечивающих доступ к большим, центральным, коллективным ресурсам таким, как, например, вычислительные серверы и файловые серверы. Для центральных машин, будущая волна мультипроцессоров с объединенной памятью казалась очевидным кандидатом. Философия является очень похожей на ту самую Cambridge Distributed System [NeHe82]. Первым понятным постулатом была необходимость сформировать UNIX из множества небольших систем, а не систему из множества UNIX'ов.
Проблемы с UNIX были слишком глубокими для того, чтобы их можно было решить, но некоторые идеи могли быть использованы. Наилучшим было ее использование файловой системы для координации присваивания имен и получения доступа к ресурсам, даже таким, как, например, устройства, по традиции не рассматриваемые как файлы. Для Plan 9 мы приняли эту идею, разработав протокол сетевого уровня, названный 9P, чтобы позволить машинам получать доступ к файлам на удаленных системах. Над этим мы надстроили систему присваивания имен, которая позволяет людям и их вычисляющим агентам формировать модифицируемые представления ресурсов в сети. Здесь у Plan 9 появляются отличия: пользователь Plan 9 формирует личную среду работы и воссоздает ее, где бы ни захотел, а не занимается всей работой на личной машине. Скоро стало ясным, что эта модель более богата возможностями, чем мы предвидели, и идеи пространства имен для каждого процесса и файлоподобных системных ресурсов были расширены для всех системных процессов, графики и даже самой сети.
К 1989, система стала достаточно целостной, для того чтобы некоторые из нас начали использовать ее в качестве своей основной рабочей среды. Это означало внедрение многих служб и приложений, к которым мы привыкли в UNIX. Мы использовали эту возможность, чтобы вернуться вновь ко множеству вопросов, а не только к вопросам резидентного ядра, которые, как мы почувствовали, UNIX решает плохо. Plan 9 обладает новыми компиляторами, языками, библиотеками, оконной системой, и множеством новых приложений. Многие старые инструментальные средства были отброшены, пока вышеприведенное не было отшлифовано или переписано.
Почему так всеобъемлюще? Различие между операционной системой, библиотекой, и приложением важно для исследователя операционной системы, но неинтересно пользователю. То, что имеет значение – это ясное функционирование. Формируя полностью новую систему, мы были способны решить проблемы, где, как мы думали, они должны быть решены. Например, нет реального "tty драйвера" в ядре; это – работа оконной системы. В современном мире существенно наличие компьютеров со множеством архитектур от множества производителей, однако, под обычными компиляторами и инструментальными средствами подразумеваются программы, созданные для того, чтобы выполняться локально; нам нужно пересмотреть заново эти вопросы. Наиболее важным, тем не менее, тестом системы является вычислительная среда, которую она предоставляет. Создание более эффективного способа работы "старых боевых коней" UNIX'а является пустой тратой времени; мы были более заинтересованы в том, содействуют ли новые идеи предложенные архитектурой основной системы более эффективному методу работы. Таким образом, хотя Plan 9 обеспечивает среду эмуляции для выполнения команд POSIX, это – след системы. Большинство системного программного обеспечения разработано в среде "исконного" Plan 9.
Существуют преимущества в обладании полностью новой системой. Изначально наша лаборатория создавала экспериментальные периферийные платы. Для того чтобы облегчить написание драйверов устройств, нам требуется система, которая доступна в форме исходных кодов (больше не гарантируется для UNIX, даже в родной лаборатории). Также, нам требуется перераспределить нашу работу, что означает необходимость локального создания программного обеспечения. Например, мы могли бы использовать некоторые компиляторы поставщиков C для нашей системы, но даже если бы преодолели проблемы с перекрестной компиляцией, у нас были трудности с перераспределением результатов.
Эта статья служит в качестве обзора системы. В ней обсуждается архитектура от самых низких строительных блоков до вычислительной среды, которую видят пользователи. Она также служит в качестве введения в остальную часть "Руководства программиста Plan 9", которым она сопровождается. Более детально о темах этой статьи может прочитать где-нибудь еще в руководстве.
Дизайн
Внешний вид системы создан на основе трех принципов. Во-первых, ресурсы получают имена и доступ подобно файлам в иерархической файловой системе. Во-вторых, существует стандартный протокол, названый 9P, для доступа к этим ресурсам. В-третьих, несовместимые иерархии, предоставляемые различными службами, объединяются вместе в единое иерархическое пространство имен файлов. Необычные свойства Plan 9 происходят от последовательного настойчивого применения этих принципов.
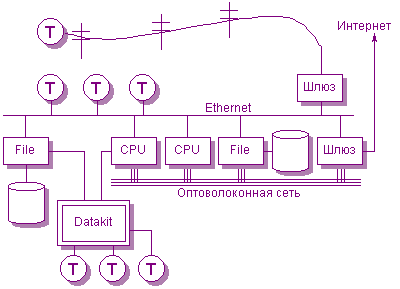
Большая установка Plan 9 имеет некоторое количество компьютеров, соединенных в сеть, каждый из которых обеспечивает конкретный класс служб. Общие многопроцессорные серверы обеспечивают вычислительные циклы; другие большие машины предлагают хранение файлов. Эти машины расположены в кондиционируемой комнате и связаны быстродействующими сетями. Сети с меньшей шириной полосы частот, например, Ethernet или ISDN, подключают эти серверы к рабочим станция, расположенных в офисах или домах, или к PC, называемым терминалами в терминологии Plan 9. Рис. 1 показывает это расположение.
 |
|
Рис. 1. Структура большой установки Plan 9. Серверы CPU и файловые серверы совместно используют быстрые локальные сети, в то время как терминалы используют более медленные сети на большей территории, такие как Ethernet, Datakit или телефонные линии для соединения с ними. Машины-шлюзы, которые являются всего лишь серверами CPU, присоединяются ко множеству сетей, позволяя машинами одной сети видеть другую. |
Современный стиль обработки данных предлагает каждому пользователю выделенную рабочую станцию или PC. У Plan 9 другой метод. Различные машины с экранами, клавиатурами и мышами обеспечивают доступ к ресурсам сети таким образом, что они являются функционально эквивалентными, наподобие терминалов, подключенных к старой системе разделения времени. Однако когда кто-нибудь использует систему, терминал временно персонализируется этим пользователем. Вместо модификации аппаратных средств, Plan 9 предлагает способность модифицировать вид системы, предусмотренный программным обеспечением. Эта настройка выполнена путем предоставления локальных персональных имен для совместно используемых ресурсов в сети. Plan 9 предоставляет механизм для создания персонального представления общего пространства с локальными именами для глобально доступных ресурсов. С тех пор, как наиболее важные ресурсы сети являются файлами, модель этого вида является файлово-ориентированной.
Локальное пространство имен клиента обеспечивает способ настройки представления сети пользователя. Все службы, доступные в сети, экспортируют файловые иерархии. Иерархии, важные для пользователя, собираются вместе в настраиваемом пространстве имен; иерархии, не представляющие никакого непосредственного интереса игнорируются. Ниже описывается стиль использования отличный от идеи "единого глобального пространства имен". В Plan 9 существуют известные имена служб, и единые имена файлов экспортируются этими службами, но их представление полностью локально. Как аналогию рассмотрим разницу между фразой "мой дом" и точным адресом дома говорящего. Второй вариант может быть использован каждым, но первый легче сказать, и имеет смысл после проговаривания. Он также изменяет значение в зависимости от того, кто говорит, однако, это не вызывает неразбериху. Аналогично, в Plan 9 имя /dev/cons всегда имеет отношение к терминалу пользователя и /bin/date – правильная версия команды date, но то, какие файлы эти имена представляют, зависит от обстоятельств, таких как, например, архитектура машины, выполняющей date. Plan 9, в таком случае, имеет локальные пространства имен, которые подчиняются глобально понимаемым соглашениям; эти соглашения гарантируют нормальное поведение в присутствии локальных имен.
Протокол 9P структурирован как набор протоколов, которые посылают запрос от клиента к серверу (локальному или удаленному) и возвращают результат. 9P контролирует файловые системы, а не только файлы: он включает процедуры для обработки файловых имен и просмотра иерархии имен файловой системы, предоставляемой сервером. С другой стороны, пространство имен клиента содержится в единственной системе клиента, а не "на" или "с" сервером, в отличие от таких систем как, например, Sprite [OCDNW88]. Также, доступ к файлам осуществляется на уровне байтов, а не блоков, что отличает 9P от протоколов, подобных NFS и RFS. В статье Уэлша (Welch) сравниваются файловые системы сетей Sprite, NFS, и Plan 9 [Welc94].
Этот метод был разработан с учетом традиционных файлов, но может быть расширен и на многие другие ресурсы. Службы Plan 9, которые экспортируют файловые иерархии, включают устройства ввода/вывода, службы резервного копирования, оконная система, сетевые интерфейсы и многие другие. Пример – файловая система процессов, /proc, которая обеспечивает очень мощный способ проверки и управления для работающих процессов. В предшествующих системах встречалась аналогичная идея [Kill84], но Plan 9 значительно расширил понятие файлов [PPTTW93]. Файловая системная модель понятна как системным разработчикам, так и общим пользователям, так что службы, которые представляют подобные файловые интерфейсы легко создавать, понимать и использовать. Файлы создаются в соответствии с согласованными правилами защиты, присваивания имен и получения доступа как локального, так и дистанцированного, так что службы, созданные этим способом готовы для работы в распределенной системе. (Это – отличие от "объектно-ориентированных" моделей, где эти вопросы должны решаться заново для каждого класса объекта). Примеры в последующих разделах иллюстрируют эти идеи в действии.
Обзор командного уровня
Предполагается, что Plan 9 будет использоваться на машине, где работает оконная система. У него нет понятия "телетайпа" в понятии UNIX. Обработка клавиатуры чистой системы – элементарна, но как только оконная система, 8½ [Pike91], запускается, текст может быть отредактирован операциями "cut and paste" из всплывающих меню, скопирован между окнами, и так далее. 8½ разрешает редактировать текст из прошлого, а не только в текущей строке ввода. Возможности текстового редактирования 8½ достаточно мощны, чтобы вытеснить специальные возможности такие как, например, историю в оболочке, подкачку и прокрутку, редакторы почты. Окна 8½ не поддерживают адресацию курсора и, за исключением одного терминального эмулятора для упрощения соединения с традиционными системами, в Plan 9 нет курсор-адресуемого программного обеспечения.
Каждое окно создается в отдельном пространстве имен. Установки, сделанные для пространства имен в окне не влияют на другое окно или программы, что делает это безопасным для экспериментирования с локальными модификациями в пространства имен, например для замены файлов из файловой системы дампа при отладке. Как только отладка завершена, окно может быть удалено и весь экспериментальный инструментарий пропадет. Подобные рассуждения применимые к частным пространствам каждого окна имеются и для переменных среды, сообщение (аналог сигналов UNIX), и т.п.
Каждое создаваемое окно выполняет приложение, такое как shell, со стандартным вводом и выводом, подключенными к редактируемому тексту окна. Каждое окно также имеет частное побитовое отображение и мультиплексный доступ к клавиатуре, мыши, и другим графическим ресурсам с помощью файлов, подобных /dev/mouse, /dev/bitblt, и /dev/cons (аналог /dev/tty в UNIX). Эти файлы предоставлены 8½, которая работает как файловый сервер. В отличие от окон X, где новое приложение обычно создает новое окно для работы, в 8½ графическое приложение обычно работает в окне, в котором оно запускается. Возможно, и эффективно для приложений создавать новые окна, но это не является стилем системы. Снова контрастируя с X, в которой удаленное приложение делает сетевой вызов сервера X, чтобы начать выполнение, дистанционное приложение 8½ видит файлы mouse, bitblt, и cons для окна как обычно в /dev; оно не знает, являются ли файлы локальными. Оно просто читает и записывает их для управления окном; сетевое соединение уже здесь, причем мультиплексное.
Предполагаемый стиль использования – запуск диалоговых приложений таких, как оконная система и текстовый редактор на терминале, и запуск приложений, требующих интенсивных вычислений и работы с файлами на удаленных серверах. Разные окна могут выполнять программы на разных машинах в разных сетях, но путем создания эквивалентных пространств имен для всех окон, этот стиль остается прозрачным: доступны те же команды и ресурсы с теми же именами где бы ни выполнялось вычисление.
Набор команд Plan 9 подобен набору UNIX'а. Команды делятся на несколько свободных классов. Некоторые являются новыми программами для старых задач: программы, подобные ls, cat, и who, которые имеют похожие имена и функции, но являются новыми, более простыми реализациями. Who, например, – сценарий shell, тогда как ps – просто 95 строк кода C. Некоторые команды являются по существу такими же, как и их предки из UNIX: awk, troff, и другие были преобразованы в ANSI C и расширены для обработки Unicode, но все же остались привычными инструментальными средствами. Некоторые – полностью новые программы для старых ниш: оболочка rc, текстовый редактор sam, отладчик acid и другие замещают хорошо известные инструментальные средства UNIX с аналогичными задачами. Наконец, около половины команд являются новыми.
Совместимость не была требованием для системы. Там, где старые команды или система обозначений казались достаточно хорошими, мы сохранили их. В противном случае, мы заменяли их.
Файловый Сервер
Центральный файловый сервер сохраняет долговременные файлы и предоставляет их для сети как файловую иерархию, экспортированную с использованием 9P. Сервер является автономной системой, доступ к которой происходит только через сеть, разработанной для отличного выполнения своей единственной работы. Он не выполняет никаких процессов пользователя, только фиксированный набор стандартных программ, скомпилированных в загрузочный образ. Главная иерархия, экспортируемая сервером, является единым деревом, представляющим файлы на множестве дисков, а не набором дисков или отдельных файловых систем. Эта иерархия совместно используется многими пользователями на обширной территории во множестве сетей. Другие файловые деревья, экспортируемые сервером, включают специализированные системы, такие как, например, временная память и, как объяснено ниже, службу резервного копирования.
Файловый сервер имеет три уровня памяти. Центральный сервер в нашей конфигурации имеет около 100 мегабайт буферов памяти, 27 гигабайт магнитных дисков, и 350 гигабайт запоминающих устройств большого объема на дисководах WORM (write-once-read-many). Диск является кешем для WORM, а память является кешем для диска; каждый из них значительно быстрее и обеспечивает на порядок большее пропускание, чем уровень, который он кэширует. Адресуемые данные в файловой системе могут быть большими, чем размер магнитных дисков, поскольку они – только кэш; наш основной файловый сервер имеет около 40 гигабайт активной памяти.
Наиболее необычная возможность файлового сервера исходит из его использования устройств WORM для постоянного хранения. Каждое утро в 5 часов, автоматически происходит дамп файловой системы. Файловая система замораживается и все блоки, модифицированные со времени последнего дампа ставятся в очередь записи на WORM. Как только блоки будут поставлены в очередь, служба восстанавливается и корень дампированной файловой системы, доступной только для чтения, появляется в иерархии всех когда-либо созданных дампов, названный по дате создания. Например, каталог /n/dump/1995/0315 является корневым каталогом образа файловой системы в том виде, в котором он оказался ранним утром 15 марта 1995 года. Постановка в очередь блоков занимает несколько минут, но процесс копирования блоков на WORM, который работает в фоне, может занимать часы.
Есть два способа использования файловой системы дампов. Первый – самими пользователями, которые могут просматривать файловую систему дампа непосредственно или подключать ее части к своему пространству имен. Например, чтобы отследить дефект, достаточно просто попробовать компилятор трехмесячной давности или скомпоновать программу с вчерашней библиотекой. С ежедневными снимками всех файлов проще найти, когда было сделано конкретное изменение или какие изменения были сделаны в конкретный день. Люди свободно вносят большие исследовательские изменения в файлы, зная, что они могут быть восстановлены единственной командой copy. Не существует как таковой системы резервного копирования; взамен этого, поскольку дамп находится в пространстве имен файлов, проблемы резервирования могут быть решены стандартными инструментальными средствами, такими как, например, cp, ls, grep, и diff.
Другим (очень редким) использованием является полное резервное копирование системы. В случае аварийной ситуации активная файловая система может быть инициализирована из любого дампа путем очистки дискового кэша и настройки корня активной файловой системы так, чтобы он был копией дампированного корня. Хотя и легко реализуемый, этот метод не дается легко: кроме потери любых изменений, сделанных после даты дампирования, этот метод восстановления очень сильно замедляет работу системы. Кеш должен быть перезагружен с WORM, которые значительно медленнее, чем магнитные диски. Перезагрузка рабочего состояния файловой системы и восстановление ее полных эксплуатационных качеств занимает несколько дней.
Права доступа к файлам в дампе такие же, как и при создании дампа. Обычные утилиты имеют обычные права в дампе, без какого бы то ни было специального приспособления. Тем не менее, файловая система дампа предназначена только для чтения, что означает, что файлы в дампе не могут быть записаны независимо от их битов доступа; фактически, как только каталоги становятся структурами, предназначенными только для чтения, даже разрешения не могут быть изменены.
Как только файл записан на WORM, он не может быть удален, так что наши пользователи никогда не видят сообщения "пожалуйста, очистите Ваши файлы" и не существует команды df. Мы считаем WORM-дисководы с автоматической сменой дисков неограниченным ресурсом. Единственной проблемой является время, которое потребуется, чтобы заполнить его. Наш WORM обслуживал сообщество около 50 пользователей в течение пяти лет и поглощал ежедневные дампы, затратив в общей сложности 65% памяти дисковода. В течение этого времени, изготовитель улучшил технологию, удваивающую емкость индивидуальных дисков. Если бы мы должны были модернизировать оборудование, у нас было бы больше свободного пространства, чем на исходном пустом дисководе. Технология создала запоминающие устройства быстрее, чем мы смогли использовать их.
Необычные файловые серверы
Plan 9 характеризуется наличием ряда серверов, которые предоставляют файлоподобный интерфейс для необычных служб. Многие из них осуществляются процессами пользовательского уровня, хотя это различие неважно для их клиентов; обеспечивается ли услуга ядром, процессом пользователя, или удаленным сервером не имеет отношения к способу ее использования. Существуют дюжины таких серверов; в этом разделе мы представим три их представителя.
Возможно, наиболее замечательный файловый сервер в Plan 9 – это 8½ – оконная система. Более подробно она обсуждается в другом месте [Pike91], но заслуживает краткого описания здесь. 8½ предоставляется два интерфейса: пользователю, сидящему за терминалом, она предлагает традиционный стиль взаимодействия с многочисленными окнами, в каждом из которых выполняется приложение, и все это управляется мышью и клавиатурой. Для клиентских программ представление также довольно традиционно: программы, работающие в окне, видят набор файлов в /dev с именами, подобными mouse, screen и cons. Программы, которые хотят напечатать текст в своем окне, пишут в /dev/cons; чтобы прочитать состояние мыши, они читают /dev/mouse. В стиле Plan 9, растровая графика осуществлена путем обеспечения файла /dev/bitblt, в который клиенты записывают закодированные сообщения для выполнения графических операций, таких как bitblt (RasterOp). Что необычно – метод реализации этого: 8½ – файловый сервер, предоставляющий файлы в /dev клиентам, работающим в каждом окне. Хотя, каждое окно выглядит одинаково для своего клиента, каждое окно имеет индивидуальный набор файлов в /dev. ½ мультиплексирует доступ клиентов к ресурсам терминала, обслуживая многочисленные комплекты файлов. Каждому клиенту дают частное пространство имен с другим набором файлов, которое ведет себя так же, как и во всех других окнах. У этой структуры есть много преимуществ. Одно из них – это то, что 8½ обслуживает те же файлы, в которых он нуждается для своей собственной реализации, она мультиплексирует собственный интерфейс, таким образом, она может быть запущена рекурсивно как клиент самой себя. Также, примите во внимание реализацию /dev/tty в UNIX, которая требует специальный код ядра для переназначения открытых вызовов на соответствующее устройство. Взамен этого в 8½ эквивалентная служба работает автоматически: 8½ обслуживает /dev/cons как свою основную функцию; ничего дополнительно делать не надо. Когда программа хочет читать с клавиатуры, она открывает /dev/cons, но это – частный, а не общий файл с особыми свойствами. Снова локальные пространства имен делают это возможным; соглашения о взаимодействии файлов в их пределах делают это естественным.
8½ обладает уникальной характеристикой, которая стала возможной благодаря ее дизайну. Поскольку она осуществлена как файловый сервер, у нее есть возможность откладывать ответ на запросы чтения для отдельных окон. Такое поведение переключается зарезервированной кнопкой на клавиатуре. Одиночное нажатие временно прекращает чтение клиентом из окна; повторное нажатие восстанавливает нормальное чтение, которое поглощает любой подготовленный текст построчно. Это позволяет пользователям вводить многострочный входной текст на экране прежде, чем приложение увидит его, избегая необходимости вызова отдельного редактора для подготовки текста такого, как, например, почтового сообщения. Связанно, свойство заключается в том, что чтение происходит непосредственно из структуры данных, определяющей текст на дисплее: текст можно редактировать до тех пор, пока его конечная строка не сделает приготовленную строку текста доступной для чтения клиентом. Даже после этого, пока строка не прочитана, текст, который клиент прочитает, может быть изменен. Например, после введения
% make rm *
в оболочку, пользователь может переместиться на позицию над завершающей новой строкой в любое время до завершения, задержать выполнение команды rm, или даже указать мышью позицию до rm и набрать другую команду, которую нужно выполнить сначала.
В Plan 9 нет команды ftp. Взамен этого файловый сервер пользовательского уровня, названный ftpfs соединяется с FTP сайтами, подключается от имени пользователя и использует протокол FTP для просмотра файлов в удаленном каталоге. Локальному пользователю он предоставляет файловую иерархию, подключенную к /n/ftp в локальном пространстве имен, зеркально отражающую содержимое FTP сайта. Другими словами, он переводит протокол FTP в 9P, чтобы обеспечить для Plan 9 доступ к FTP сайтам. Реализация мудреная; ftpfs должен производить немного более сложное кэширование для эффективности и использовать эвристику, чтобы декодировать информацию удаленного каталога. Но результат стоящий: все локальные файловые инструментальные средства управления как, например, cp, grep, diff, и, конечно, ls пригодны для файлов, расположенных на FTP сервере, точно так же, как и для локальных файлов. Другие системы, такие как Jade и Prospero, используют ту же возможность [Rao81, Neu92], но из-за локальных пространств имен и простоты реализации 9P, этот подход более естественен в Plan 9, чем в других средах.
Один сервер – exportfs – это процесс пользователя, который берет часть своего собственного пространства имен и делает его доступным для других процессов путем перевода запросов 9P в системные вызовы ядра Plan 9. Файловая иерархия, которую он экспортирует, может содержать файлы многочисленных серверов. Exportfs обычно работает как удаленный сервер, запускаемый локальной программой или import, или cpu. Import делает сетевой вызов к удаленной машине, запускает exportfs там и подключает свое соединение 9P к локальному пространству имен. Например,
делает сетевые интерфейсы Helix видимыми в локальном каталоге /net. Helix является центральным сервером и имеет множество сетевых интерфейсов, так что это позволяет машине с одним типом сети получить доступ к любой из сетей Helix. После такого импорта, локальная машина может делать вызовы любой из сетей, подключенных к Helix. Другим примером является команда
которая делает процессы Helix видимыми в локальном каталоге /proc, разрешая локальным программам отладки изучать удаленные процессы.
Команда cpu подключает локальный терминал к удаленному серверу CPU. Она работает в направлении, противоположном import: после вызова сервера, она локально запускает exportfs и монтирует его в пространство имен процесса, обычно вновь созданного shell на сервере. Затем она перестраивает пространство имен, чтобы сделать локальными файлы устройств (такие как, обслуживаемые оконной системой терминала) видимыми в каталоге /dev сервера. Эффектом запуска команды cpu является, следовательно, запуск shell на быстрой машине, еще более плотно связанной с файловым сервером, с пространством имен, аналогичным локальному. Все файлы локальных устройств видимы дистанционно, так что удаленные приложения имеют полный доступ к локальным сервисам, таким как растровая графика, /dev, /cons и так далее. Это не схоже ни с rlogin, который ничего не делает для воспроизведения локального пространства имен в удаленной системе, ни с разделением файлов с, скажем, NFS, которое может достичь некоторой эквивалентности пространств имен, но не комбинация доступа к локальным аппаратным устройствам, удаленным файлам и удаленным ресурсам CPU. Команда cpu является однозначно прозрачным механизмом. Например, разумно запустить оконную систему в окне, выполняющим команду cpu; все окна, созданные там автоматически запускают процессы на сервере CPU.
Конфигурируемость и администрирование
Единая взаимосвязь компонентов в Plan 9 делает возможным конфигурирование установки Plan 9 множеством различных способов. Единственный портативный PC может функционировать как отдельная система Plan 9; в другом крайнем случае, наша установка имеет центральные многопроцессорные серверы CPU, файловые серверы и множество терминалов, колеблющихся от небольших PC до профессиональных графических рабочих станций. Это такая большая установка, которая наилучшим образом представляет как действует Plan 9.
Системное программное обеспечение является переносимым и одна и та же операционная система работает на всех аппаратных средствах. За исключением производительности, внешний вид системы на, скажем, рабочей станции SGI такой же, как и на портативном компьютере. Поскольку обработка данных и файловые службы централизованы, и терминалы не имеют постоянных запоминающих устройств, все терминалы функционально идентичны. Таким образом, Plan 9 имеет одно из хороших свойств старых систем разделения времени, где пользователь мог бы сесть перед любой машиной и видеть ту же систему. В современном сообществе рабочих станций, машины стремятся принадлежать людям, которые переделывают их, храня частную информацию на локальном диске. Мы отвергли этот стиль использования, хотя система может использоваться таким образом. В нашей группе, у нас есть лаборатория с множеством машин с открытым доступом, и пользователь может сесть за любую из них и работать.
Центральные файловые серверы централизуют не только файлы, но и их администрирование и эксплуатацию. Фактически один сервер является основным, содержащим все системные файлы; другие серверы обеспечивают дополнительную память или доступны для отладки и других специальных нужд, но системное программное обеспечение находится на одной машине. Это означает, что каждая программа имеет единственную копию двоичного кода для каждой архитектуры, так что установка обновлений и исправлений становится банальной задачей. Также существует единственная база данных пользователей; нет необходимости синхронизировать индивидуальные файлы /etc/passwd. С другой стороны, зависимость от единственного центрального сервера ограничивает размер установки.
Другим примером мощи централизованной файловой службы является способ управления системой Plan 9 сетевой информацией. На центральном сервере есть каталог /lib/ndb, который содержит всю информацию, необходимую для управления локальными Ethernet и другими сетями. Все машины используют ту же базу данных для общения с сетью; нет необходимости управлять распределенной системой присваивания имен или следить за взаимосоответствием параллельных файлов. Для того чтобы установить новую машину в локальной сети Ethernet, выберите имя и IP адрес и добавьте их к единственному файлу в /lib/ndb; все машины в установке будут способны соединиться с ней немедленно. Для того чтобы начать работать, подключите машину к сети, включите ее и используйте BOOTP и TFTP для загрузки ядра. Все остальное произойдет автоматически.
Наконец, файловая система автоматизированного дампа освобождает всех пользователей от необходимости поддержки их систем, при обеспечении доступа к резервному копированию файлов без носителей на магнитных лентах, специальных команд или участия обслуживающего персонала. Трудно преувеличить улучшения в образе жизни, предоставленные этой службой.
Plan 9 работает на множестве аппаратных средств без ограничений на конфигурирование установки. В нашей лаборатории мы решили использовать центральные серверы, поскольку они амортизируют издержки и управление. Признак того, что это хорошее решение – то, что наши дешевые терминалы остаются комфортабельными местами для работы приблизительно по пять лет, значительно дольше, чем рабочие станции, которые должны обеспечить полную вычислительную среду. Мы делаем, тем не менее, модернизацию центральных машины, так что обслуживание, доступное даже от старых терминалов Plan 9 улучшается со временем. Деньги, сохраненные путем избежания регулярной модернизации терминалов, взамен истрачены на новейшие самые быстрые многопроцессорные серверы. Мы оцениваем эти издержки в половину стоимости сетевых рабочих станций, которые пока обеспечивают общий доступ к более мощным машинам.
Программирование на C
Утилиты Plan 9 написаны на нескольких языках. Некоторые – сценарии для shell, например, rc [Duff90]; масса написана на новом C-подобном языке, названном Alef [Wint95], описанном ниже. Преимущественное большинство, все же, написаны на диалекте ANSI C [ANSIC]. Большинство из них – полностью новые программы, но некоторые берут начало в коде до-ANSI C из нашей исследовательской системы UNIX [UNIX85]. Они обновлены до ANSI C и переработаны для переносимости и аккуратности.
Диалект C системы Plan 9 имеет немного незначительных расширений, описанных в [Pike95], и несколько крупных ограничений. Наиболее важное ограничение – в том, что компилятор требует, чтобы все определения функций имели прототипы ANSI и все вызовы функций появлялись в области видимости описания прототипа функции. Как стилистическое правило, описания прототипов помещаются в заголовочные файлы, включаемые всеми файлами, которые вызывают функцию. Каждая системная библиотека имеет связанный заголовочный файл, объявляющий все функции в этой библиотеке. Например, стандартная библиотека Plan 9 называется libc, так что все исходные файлы C включают <libc.h>. Эти правила гарантируют, что все функции вызываются с аргументами, имеющими ожидаемые типы, что было не всегда верно для программ до-ANSI C.
Другое ограничение состоит в том, что компиляторы C допускают только подмножество директив препроцессора, требуемых ANSI. Основной пропуск – #if, так мы считаем, что он никогда не бывает необходим, и им часто злоупотребляют. Также, его эффект лучше достигается другими средствами. Например, #if, использованный для переключения возможностей при компиляции, может быть записан как обычный оператор if, полагающийся на свертывание констант во время компиляции и удаление "мертвого кода" при создании объектного кода.
Условная компиляция, даже с #ifdef, используется в Plan 9 умеренно. Единственные архитектурно-зависимые #ifdef в системе находятся в программах низкого уровня графической библиотеки. Взамен, мы избегаем таких зависимостей или, когда необходимо, изолируем их в отдельных исходных файлах или библиотеках. Кроме затруднения чтения кода, #ifdef делают невозможным знание о том какой исходный код компилируется в двоичный код или о том будет ли компилироваться и работать правильно защищаемый ими код. Они затрудняют поддержку программного обеспечения.
Стандартная библиотека Plan 9 перекрывает большие части ANSI C и POSIX [POSIX], но отличается, когда определяются цели или реализация Plan 9. Когда семантика функции изменялась, мы также изменяли ее имя. Например, вместо creat, в Plan 9 есть функция create, которая принимает три аргумента: два подлинных плюс третий, который, подобно второму аргументу open, определяет должен ли возвращаемый файловый дескриптор быть открыт для чтения, записи или и для того, и для другого. Такая схема вынуждена путем осуществления создания протоколом 9P, но она также упрощает общее create для инициализации временных файлов.
Другим отступлением от ANSI C является то, что Plan 9 использует 16-битовый набор символов, называющийся Unicode [ISO10646, Unicode]. Хотя мы почти прекратили полную интернационализацию, Plan 9 трактует представление всех основных языков единообразно во всем программном обеспечении. Для того чтобы упростить обмен текстом между программами, символы сжаты в байтовый поток путем кодирования, которое мы разработали, названного UTF-8, который теперь принимается как стандарт [FSSUTF]. У него есть несколько привлекательных свойств, включая независимость от порядка байтов, обратную совместимости с ASCII, и удобство реализации.
Существует множество проблем в адаптации существующего программного обеспечения к большому набору символов с кодированием, которое представляет символы с переменным количеством байтов. ANSI C пытается решить некоторые вопросы, но не достигает цели в решении их всех. Он не подбирает кодирование набора символов и не определяет все необходимые процедуры библиотеки ввода/вывода. Кроме того, функции, которые он определяет, имеют технические проблемы. Так как стандарт оставил слишком много нерешенных проблем, мы решили построить наш собственный интерфейс. Детали изложены в отдельной статье [Pike93].
Небольшой класс программ Plan 9 не следуют соглашениям, обсужденным в этом разделе. Это импортированные программы, обслуживаемые сообществом UNIX; tex – представительный пример этого класса. Для того чтобы избежать перевода таких программ каждый раз, когда выпускается новая версия, мы создали среду переноса, названную ANSI C/POSIX Environment, или APE [Tric95]. APE содержит раздельные включаемые файлы, библиотеки и команды, соответствующие насколько возможно строгой спецификации ANSI C и спецификации POSIX базового уровня. Для того чтобы перенести сетевое программное обеспечение, такое как, например, X Windows, необходимо было добавить некоторые расширения к этим спецификациям, как, например, сетевые функции BSD.
Переносимость и компиляция
Plan 9 переносим на многие архитектуры процессоров. В течение одного сеанса работы с компьютером, обычно использование нескольких архитектур: возможно, оконная система работает на процессоре Intel, подключенном к CPU серверу, базирующемуся на MIPS с файлами, находящимися на системе SPARC. Для того чтобы такая неоднородность была прозрачной, должны быть соглашения об обмене данными между программами; для того, чтобы использование программ было простым, должны быть соглашения о кросс-платформенной компиляции.
Для того чтобы избежать проблем с порядком байтов данные передаются между программами практически всегда как текст. Иногда, все же, объем данных достаточно велик для того, чтобы был необходим двоичный формат; такие данные передаются как байтовый поток с предопределенным кодированием для многобайтовых величин. В редких случаях, когда формат является достаточно сложным для того, чтобы быть определенным структурой данных, структура никогда не передается как целое; вместо этого, она разлагается на составляющие поля, закодированные как упорядоченный байтовый поток, и затем заново собирается получателем. Эти соглашения влияют на данные от ядра или информации о состоянии прикладной программы до промежуточных объектных файлов, созданных компилятором.
Программы, включая ядро, часто пересылают свои данные через интерфейс файловой системы, механизм доступа, которые является наследственно переносимым. Например, системные часы представлены десятичным числом в файле /dev/time; библиотечная функция времени (нет системной функции time), читает файл и преобразовывает его в двоичный код. Аналогично, вместо кодирования состояния прикладного процесса в наборе флагов и битов в частной памяти, ядро пересылает текстовую строку в файл, названный status в файловой системе /proc, связанной с каждым процессом. Команда ps в Plan 9 тривиальна: она печатает содержимое желаемых файлов статуса после некоторого незначительного переформатирования; кроме того, после
локальная команда ps сообщает о статусе процессов Helix.
Каждая поддерживаемая архитектура работает с собственными компиляторами и загрузчиками. Компиляторы C и Alef могут создавать промежуточные файлы, которые компактно закодированы; содержимое уникально для целевой архитектуры, но формат файла независим от типа процессора компиляции. Когда компилятор для данной архитектуры компилируется для другого типа процессора, и затем используется для компиляции программ на нем, промежуточные файлы, созданные на новой архитектуре, идентичны созданным на исходном процессоре. С точки зрения компилятора, каждая компиляция является перекрестной компиляцией.
Хотя загрузчики каждой архитектуры принимают только промежуточные файлы, созданные компиляторами для этой архитектуры, такие файлы могут быть сгенерированы компилятором, выполняющимся на любом типе процессора. Например, возможно запустить компилятор MIPS на 486, а затем использовать загрузчик MIPS на SPARC для создания программы MIPS.
Поскольку Plan 9 работает на множестве архитектур даже в одной установке, различение компиляторов и имен промежуточных файлов упрощает мультиархитектурную разработку из единственного исходного кода. Компиляторы и загрузчики для каждой архитектуры названы однозначно; нет команды cc. Имена производятся конкатенацией кодовой буквы, связанной с целевой архитектурой, с именем компилятора или загрузчика. Например, буква "8" – кодовая буква для x86 процессоров Intel; компилятор C назван 8c, компилятор Alef – 8al, и загрузчик назван 8l. Аналогично, промежуточные файлы компилятора имеют расширение.8, а не.o.
Программа-построитель Plan 9 mk, родственница make, читает имена текущей и целевой архитектур из переменных среды $cputype и $objtype. По умолчанию текущий процессор – целевой, но установка $objtype в имя другой архитектуры до вызова mk имеет результатом кросс-построение:
создает программу для архитектуры SPARC независимо от выполняющей машины. Значение $objtype выбирает файл архитектурно-зависимых определений переменных, которые конфигурируют построитель для использования подходящих компилятора и загрузчика. Хотя и бесхитростная, эта техника хороша на практике: все приложения в Plan 9 созданы из единого исходного кода и возможно создавать различные архитектуры параллельно без конфликта.
Параллельное программирование
Поддержка параллельного программирования в Plan 9 имеет два аспекта. Во-первых, ядро обеспечивает простую модель процесса и несколько тщательно разработанных системных подпрограмм для синхронизации и разделения. Во-вторых, новый параллельный язык программирования, названный Alef, поддерживает одновременное программирование. Хотя возможно создание параллельных программ на C, Alef – предпочтительный параллельный язык.
Существует тенденция в новых операционных системах осуществления двух классов процессов: нормальных процессов стиля UNIX и небольших потоков ядра (нитей). Вместо этого, Plan 9 предоставляет единственный класс процессов, но допускает тонкое управление разделением ресурсами процесса, такими как память и файловые дескрипторы. Единственный класс процессов является реальным подходом в Plan 9, поскольку ядро имеет эффективный интерфейс системных вызовов и дешевое создание и планирование процессов.
Параллельные программы имеют три основных требования: управление ресурсами, распространенными между процессами; интерфейс для планировщика и синхронизацию процессов на уровне мелких структурных единиц с использованием спин-блокировки. В Plan 9, новые процессы создаются с использованием системной процедуры rfork. Rfork принимает единственный аргумент, битовый вектор, который определяет, какие из родительских ресурсов процесса должны быть обобщены, скопированы, или создаваться заново в потомке. Ресурсы, управляемые rfork, включают пространство имен, среду, таблицу дескрипторов файлов, сегменты памяти, и сообщения (аналоги сигналов UNIX в Plan 9). Один из битов регулирует, создаст ли вызов rfork новый процесс; если бит выключен, результирующая модификация ресурсов происходит в процессе, сделавшем вызов. Например, процесс вызывает rfork(RFNAMEG) для того, чтобы отсоединить свое пространство имен от родительского. Alef использует низкоуровневый fork, в котором все ресурсы, включая память, объединены родителем и потомком, аналогично созданию потока ядра во многих системах.
Признаком того, что rfork – правильная модель является многообразие путей его использования. Кроме канонического использования в библиотечной процедуре fork, трудно найти два вызова rfork с теми же самыми установленными битами; программы используют его для создания множества различных форм разделения и распределения ресурсов. Система просто с двумя типами процессов: обычными процессами и потоками не может оперировать этим разнообразием.
Есть два пути разделения памяти. Во-первых, флаг для rfork мотивирующий объединение всех сегментов памяти родителя с ребенком (кроме стека, который раздваивается, не смотря ни на что). Кроме того, новый сегмент памяти может быть подключен при использовании системной процедуры segattach; такой сегмент всегда будет обобщен между родителем и потомком.
Системная процедура rendezvous предоставляет путь для синхронизации процессов. Alef использует его для осуществления каналов связи, организации очередей блокировок, составных блокировок чтения/записи, и механизмов сна и просыпания. Rendezvous принимает два аргумента, дескриптор и значение. Когда процесс вызывает rendezvous с дескриптором, он засыпает до тех пор пока другой процесс не передаст совпадающий дескриптор. Когда пара дескрипторов совпадает, значения обмениваются между двумя процессами и в обоих вызов rendezvous возвращается. Этого примитива достаточно для осуществления полного набора подпрограмм синхронизации.
Наконец, спин-блокировка предоставляется архитектурно-зависимой библиотекой на уровне пользователя. Большинство процессоров обеспечивают элементарные инструкции test и set, которые могут быть использованы для осуществления блокировок. Примечательным исключением является MIPS R3000, так как мультипроцессоры серии SGI Power имеют специальные аппаратные средства блокировки на шине. Процессы пользователя получают доступ к аппаратным средствам блокировки, отображая страницы аппаратных средств блокировки в свои адресные пространства, используя системную процедуру segattach.
Процесс Plan 9 при системном вызове будет заблокирован независимо от своего 'веса'. Это означает, что когда программа хочет читать с медленного устройства, не блокируя работу в целом, она должна породить процесс для того, чтобы осуществлять чтение для нее. Решением является запуск процесса-спутника, который осуществляет ввод/вывод и доставляет ответы в основную программу через обобщенную память или, возможно, канал. Это звучит обременительно, но на практике работает легко и эффективно; фактически, наиболее интерактивные приложения Plan 9, даже относительно обычных приложений, написанных на C, такие как, например, текстовый редактор Sam [Pike87], работают как многопроцессовые программы.
Поддержка ядром параллельного программирования в Plan 9 – несколько сот строк переносимого кода; небольшое количество простых примитивов позволяет обрабатывать проблемы понятным образом на уровне пользователя. Хотя примитивы отлично работают из C, они особенно выразительны в Alef. Создание и управление подчиненными процессами ввода/вывода может быть написано в нескольких строках Alef, обеспечивающих основание для последовательного метода для мультиплексной передачи потоков данных между произвольными процессами. Кроме того, выполнение этого в языке, а не в ядре гарантирует последовательную семантику между всеми устройствами и обеспечивает более общие примитивы мультиплексирования. Сравните это с системной процедурой select в UNIX: select применяется только к ограниченному набору устройств, законы стиля мультипрограммирования задаются в ядре, не распространяются через сети, трудно осуществимы, и сложны в использовании.
Другой причиной важности параллельного программирования в Plan 9 является то, что многопотоковые файловые серверы пользовательского уровня являются предпочтительным путем осуществлять служб. Примеры таких серверов включают среду программирования Acme [Pike94], инструмент для экспорта пространств имен exportfs [PPTTW93], демон HTTP, и серверы сетевых имен cs и dns [PrWi93]. Сложные приложения, такие как Acme, доказывают, что аккуратная поддержка операционной системы может уменьшить трудности с написанием многопотоковых приложений без перемещения потоковости и примитивов синхронизации в ядро.
Реализация пространств имен
Процессы пользователя создают собственные пространства имен, используя три системных подпрограммы: mount, bind и unmount. Системный вызов mount подключает дерево, управляемое файловым сервером к текущему пространству имени. Перед вызовом mount, клиент должен (внешними средствами), запросить соединение с сервером в форме файлового дескриптора, который может быть записан и прочитан для передачи сообщений 9P. Этот файловый дескриптор представляет канал или сетевое соединение.
Вызов mount подключает новую иерархию к существующему пространству имен. Системная процедура bind, с другой стороны, дублирует некоторую часть существующего пространства имен в другой точке пространства имен. Системный вызов unmount позволяет удалять компоненты.
Используя bind или mount, многочисленные каталоги могут быть скомпонованы в единственной точке пространства имен. В терминологии Plan 9, она является каталогом объединения и ведет себя подобно конкатенации составляющих каталогов. Аргумент flag в bind и mount определяет позицию нового каталога в объединении, позволяя добавлять новые элементы либо в начало, либо в конец объединения, или заменить его полностью. Когда поиск файлов выполняется в объединенном каталоге, каждый компонент объединения просматривается по очереди и принимается первое совпадение; подобно этому, когда каталог объединения читается, содержимое каждого из составляющих каталогов читается в свою очередь. Объединенные каталоги – одна из наиболее широко используемых организационных возможностей пространств имен Plan 9. Например, каталог /bin создан как объединение /$cputype/bin (двоичные коды программ), /rc/bin (сценарии оболочки), и возможно других каталогов предусмотренных пользователем. Эта конструкция делает переменную оболочки $PATH ненужной.
Единственным вопросом, возникшим при использовании объединенных каталогов, был вопрос о том, какой элемент объединения получает вновь созданный файл. После нескольких разработок, мы решили следующее. По умолчанию, каталоги в объединениях не принимают новые файлы, хотя системный вызов create, примененный к существующему файлу проходит нормально. Когда каталог добавляется к объединению, флаг, переданный bind или mount, позволяет создание (свойство пространства имени) в этом каталоге. Когда файл создается с новым именем в объединении, он создается в первом каталоге объединения, в котором разрешено создание; если это создание не удается, создание в целом также не удается. Эта схема позволяет общее использование размещения частного каталога в любом месте объединения общедоступных каталогов, разрешая создание только в частном каталоге.
Условно, файловая система устройства kernel связана с каталогом /dev, но для начальной загрузки процесса построения пространства имен необходимо иметь условную запись, которая разрешает прямой доступ к устройствам без существующего пространства имен. К корневому каталогу дерева, управляемого драйвером устройства, можно получить доступ, используя синтаксис #c, где c – уникальный символ (обычно буква), определяющий тип устройства. Простые драйверы устройств обслуживают одноуровневые каталоги, содержащие несколько файлов. Например, каждый последовательный порт представлен данными и управляющий файл:
% bind –a '#t' /dev % cd /dev % ls –l eia* --rw-rw-rw- t 0 bootes bootes 0 Feb 24 21:14 eia1 --rw-rw-rw- t 0 bootes bootes 0 Feb 24 21:14 eia1ctl --rw-rw-rw- t 0 bootes bootes 0 Feb 24 21:14 eia2 --rw-rw-rw- t 0 bootes bootes 0 Feb 24 21:14 eia2ctl
Программа bind является инкапсуляцией системного вызова bind; ее флаг – a позиционирует новый каталог в конце объединения. Файлы данных eia1 и eia2 могут быть прочитаны, и в них можно писать для связи через последовательный порт. Вместо использования специальных операций над этими файлами для управления устройствами, команды записываются в файлы eia1ctl и eia2ctl, управляющие соответствующими устройствами; например, записывая текстовую строку b1200 в /dev/eia1ctl устанавливают скорость этого порта в 1200 бод. Сравните это с системным вызовом ioctl в UNIX: в Plan 9 устройства управляются текстовыми сообщениями, свободными от проблем с порядком байтов, с ясной семантикой для чтения и записи. Распространено конфигурирование или отладка устройств с использованием сценариев shell.
Это универсальное использование протокола 9P, который соединяет компоненты Plan 9 вместе для формирования распределенной системы. Вместо изобретения уникальных протоколов для каждой службы, таких как rlogin, FTP, TFTP, и окон X, Plan 9 реализует службы в терминах операций над файловыми объектами, затем используя единственный, тщательно документированный протокол для обмена информацией между компьютерами. В отличие от NFS, 9P рассматривает файлы как последовательность байтов, а не блоков. Также в отличие от NFS, 9P изменяет свои параметры в процессе работы по вызовам клиентов: клиенты выполняют дистанционные вызовы процедур для установки указателей на объекты удаленного файлового сервера. Эти указатели называются идентификаторами файлов или fid. Все операции над файлами поддерживают fid для идентифицикации объекта в удаленной файловой системе.
Протокол 9P определяет 17 сообщений, обеспечивающих средства для аутентификации пользователей, управления fid'ами относительно системы иерархии файлов, копирования fid'ов, выполнения ввода/вывода, изменения атрибутов файлов и создания и удаления файлов. Их полная спецификация изложена в разделе 5 "Руководства программиста" [9man]. Существует процедура для получения доступа к иерархии имен, предоставляемой сервером. Соединение с файловым сервером устанавливается через канал или сетевое соединение. Начальное сообщение session выполняет двухстороннюю аутентификацию между клиентом и сервером. Затем сообщение attach соединяет fid, предоставляемый клиентом к корню файлового дерева сервера. Сообщение attach включает идентификатор пользователя, выполняющего attach; в дальнейшем все fid'ы, производные от корневого fid будут иметь разрешения, связанные этим пользователем. Множество пользователей делят соединение, но каждый должен выполнить attach с целью установления его или ее личности.
Сообщение walk передвигает fid через один уровень иерархии файловой системы. Сообщение clone принимает установленный fid и создает копию, которая указывает на тот же файл, что и подлинник. Его цель в том, чтобы позволить перемещение к файлу в каталоге без потери fid самого каталога. Сообщение open соединяет fid с определенным файлом в иерархии, проверяет разрешение доступа и подготавливает fid к вводу/выводу. Сообщения read и write позволяют ввод/вывод по произвольному смещению в файле; максимальный передаваемый размер определяется протоколом. Cообщение clunk указывает, что клиент больше не использует fid. Сообщение remove ведется себя подобно clunk, но вызывает удаления файла, связанного с fid и освобождение всех ассоциированных с ним ресурсов сервера.
9P имеет две формы: RPC-сообщения, пересылаемые по каналу или сетевому соединению и процедурный интерфейс с ядром. Так как драйверы устройства kernel непосредственно адресуемы, то нет необходимости передавать сообщения для связи с ними; вместо этого каждое входное сообщение 9P осуществлено прямым вызовом процедуры. Для каждого fid ядро поддерживает локальное представление в структуре данных, названной канал, так что все операции над файлами, выполняемые ядром используют канал, подключенный к этому fid. Самым простым примером являются файловые дескрипторы процессов пользователя, которые являются индексами в массиве каналов. Таблица в ядре предоставляет список точек входа точно соответствующих сообщениям 9P для каждого устройства. Системный вызов, такой как read от пользователя переводится в один или более вызовов процедур по этой таблице, проиндексированной символом типа, сохраненным в канале: procread, eiaread, и т.п. Каждый вызов принимает, по крайней мере, один канал как аргумент. Специальный драйвер ядра, названный "монтирующий драйвер", переводит вызовы процедур в сообщения, то есть, он преобразовывает локальные вызовы процедур в дистанционные. В сущности, этот специальный драйвер становится локальным модулем доступа для файлов управляемых удаленным файловым сервером. Указатель канала в локальном вызове переводится в связанный fid в передаваемом сообщении.
Монтирующий драйвер является единственным механизмом RPC, применяемым системой. Семантика обслуживаемых файлов, а не операции, выполняемые над ними, создают конкретную службу, такую как команда cpu. Монтирующий драйвер демультиплексирует сообщения протокола, передаваемые между клиентами, использующими общий канал связи с файловым сервером. Для каждого исходящего сообщения RPC, монтирующий драйвер выделяет в памяти буфер, помеченный небольшим уникальным целым, названным тег. Ответ на RPC помечен тем же тегом, который используется монтирующим драйвером для соответствия ответа с запросом.
Представление пространства имен в ядре называется монтирующей таблицей, которая хранит список связей между каналами. Каждый элемент в монтирующей таблице содержит пару каналов: исходящий канал и входящий канал. Каждый раз, когда происходит успешное перемещение канала на новую позицию в пространстве имен, к монтирующей таблице обращаются для того, чтобы посмотреть соответствует ли исходящий канал новому имени; если это так, то входящий канал клонируется и заменяет подлинник. Объединенные каталоги осуществляются преобразованием входящего канала в список каналов: успешное обращение к объединенному каталогу и возвращает входящий канал, который образует голову списка каналов, каждый из которых представляет компонент объединенного каталога. Если обращение не может обнаружить файл в первом каталоге объединения, список перемещается, клонируется следующий компонент и совершается попытка поиска в этом каталоге.
Каждый файл в Plan 9 однозначно идентифицируется набором целых чисел: типом канала (используется как индекс таблицы вызова функций), номером сервера или устройства, отличающим сервер от других устройств того же самого типа (решается локально драйвером), и qid сформированным из двух 32-битных чисел, называемых путем и версией. Путь является уникальным файловым номером, назначенным драйвером устройства или файловым сервером при создании файла. Номер версии корректируется всякий раз, когда файл модифицируется; как описано в следующем разделе, он может быть использован, для обеспечения синхронности кеша между клиентами и серверами.
Тип и номер устройства аналогичны старшему и младшему номерам устройств в UNIX; qid аналогичен индексу. Устройство и тип подключают канал к драйверу устройства, а qid идентифицирует файл в пределах этого устройства. Если файл, полученный при обзоре, имеет те же тип, устройство и qid, что и запись в монтирующей таблице, то они являются одним и тем же файлом и производится соответствующая подстановка из монтирующей таблицы. Таким образом, реализуется пространство имен.
Кэширование файлов
Протокол 9P не имеет явной поддержки кэширования файлов на стороне клиента. Большой объем памяти центрального файлового сервера действует как коллективный кэш для всех клиентов, что уменьшает общий объем памяти, необходимый для всех машин в сети. Тем не менее, есть логичные причины для кэширования файлов на клиенте, например, медленная связь с файловый сервером.
Поле версия в qid изменяется всякий раз, когда файл модифицируется, что делает возможным осуществление некоторых слабо согласованных форм кэширования. Наиболее важный – кэширование на стороне клиента текста и сегментов данных выполняемых файлов. Когда процесс выполняет программу, файл открывается заново и версия в qid сравнивается с версией файла в кэше; если они совпадают, используется локальная копия. Тот же метод может быть использован для формирования локального кеширующего файлового сервера. Этот сервер пользовательского уровня вклинивается в соединение 9P с дистанционным сервером и проверяет трафик, копируя данные на локальный диск. Когда он обнаруживает чтение известных данных, отвечает непосредственно он, тогда как записи передаются непосредственно в кэш, в котором реализуется схема со сквозной записью, что позволяет сохранять центральную копию новейшей. Это является прозрачным для процессов на терминале и не требует никаких изменений в 9P; это хорошо работает на домашних машинах, связанных через последовательные шины. Аналогичный метод может быть применен для формирования общего кэша клиентов в неиспользуемой локальной памяти, но это еще не сделано в Plan 9.
Сетевые устройства и устройства связи
Сетевые интерфейсы – это расположенные в ядре резидентные файловые системы, аналогичные устройству EIA, описанному раньше. Вызов, настройка и отключение достигается записью текстовых строк в управляющий файл, связанный с устройством; информация посылается и получается путем чтения и записи файла данных. Структура и семантика устройств является общей для всех сетей таким образом, кроме подстановки имени файла, одна и та же процедура делает вызов, используя TCP в Ethernet как URP в Datakit [Fra80].
Этот пример иллюстрирует структуру устройства TCP:
% ls – lp /net/tcp d-r-xr-xr-x I 0 bootes bootes 0 Feb 23 20:20 0 d-r-xr-xr-x I 0 bootes bootes 0 Feb 23 20:20 1 --rw-rw-rw- I 0 bootes bootes 0 Feb 23 20:20 clone % ls – lp /net/tcp/0 --rw-rw---- I 0 rob bootes 0 Feb 23 20:20 ctl --rw-rw---- I 0 rob bootes 0 Feb 23 20:20 data --rw-rw---- I 0 rob bootes 0 Feb 23 20:20 listen --r--r--r-- I 0 bootes bootes 0 Feb 23 20:20 local --r--r--r-- I 0 bootes bootes 0 Feb 23 20:20 remote --r--r--r-- I 0 bootes bootes 0 Feb 23 20:20 status %
Верхний каталог, /net/tcp, содержит клонированный файл и каталоги для каждого соединения, пронумерованных от 0 до n. Каждый каталог соединения соответствует соединению TCP/IP. Открытие clone резервирует неиспользованное соединение и возвращает свой управляющий файл. Чтение управляющего файла возвращает текстовый номер соединения, так что процесс пользователя может создать полное имя вновь размещенного каталога соединения. Файлы local, remote и status являются диагностическими; например, remote содержит адреса (для TCP, IP – адрес и номер порта) удаленной стороны.
Вызов инициируется путем записи сообщения connect с адресом в качестве аргумента; например, чтобы открыть сессию Telnet (порт 23) на удаленной машине с IP-адресом 135.104.9.52, строка должна быть такой:
Запись в управляющий файл блокируется до тех пор, пока соединение не будет установлено; если место назначения недоступно, запись возвращает ошибку. Как только соединение будет установлено, приложение telnet читает и записывает файл data для того, чтобы общаться с удаленным демоном Telnet. На другом конце, демон Telnet должен быть запущен путем записи
в свой управляющий файл, чтобы указывать на свою готовность к получению вызовов к этому порту. Такой демон называется в Plan 9 приемник.
Единая структура сетевых устройств не может скрыть все детали адресации и связи в разнородных сетях. Например, Datakit использует текстовые иерархические адресы в отличие от 32-битовых IP-адресов, так что приложение, работающее с управляющим файлом, должно все еще знать какую сеть он представляет. Вместо того, чтобы заставлять каждое приложение знать адресацию каждой сети, Plan 9 прячет эти детали в сервере соединений, названном cs. Cs – файловая система смонтированная в определенном месте. Она предоставляет единственный управляющий файл, который приложение использует, для того, чтобы определить метод подключения к хосту. Приложение записывает символический адрес и имя службы для соединения, которое оно хочет осуществить, и считывает обратно имя файла clone для открытия и адрес для переда его передачи. Если существует множество сетей, cs предоставляет список возможных сетей и последовательность адресов для проверки; он использует эвристику для определения их порядка. Например, он представляет вариант с самой широкой полосой частот первым.
Единственная библиотечная функция dial взаимодействует с cs, чтобы установить соединение. Приложение, которое использует dial, не требует никаких изменений, даже рекомпиляции, чтобы приспособиться к новой сети; интерфейс с cs прячет детали.
Однородная структура для сетей в Plan 9 делает команду import единственной нужной для построения шлюзов.
Структура ядра для сетей
Надстройки ядра, используемые для построения каналов связи в Plan 9, называются потоками [Rit84][Presotto]. Поток является двунаправленным каналом, присоединяющим физическое или псевдоустройство к процессу пользователя. Процесс пользователя вставляет и удаляет данные на одном конце потока; процесс ядра, действующий от имени устройства, работает на другом конце. Поток включает линейный список обрабатывающих модулей. Каждый модуль имеет как верхнепотоковую (по отношению к процессу), так и нижнепотоковую (по отношению к устройству) размещающую процедуру. Вызов размещающей процедуры модуля на любом конце потока вставляет данные в поток. Каждый модуль вызывает последующий для пересылки данных вверх или вниз по потоку. Подобно потокам UNIX [Rit84], потоки Plan 9 могут быть сконфигурированы динамически.
Протокол IL
Протокол 9P должен работать над надежным протоколом транспорта с ограниченными сообщениями. 9P не имеет механизма восстановления от ошибок передачи и система предполагает, что каждое чтение из канала связи возвращает единственное сообщение 9P; она не выполняет анализ потока данных, для определения границы сообщения. Каналы и некоторые сетевые протоколы уже имеют эти свойства, но стандартные протоколы IP – нет. TCP не разграничивал сообщения, пока UDP [RFC768] не предоставил надежной внутренней передачи.
Мы разработали новый протокол IL (Internet Link) для передачи сообщений 9P через IP. Это протокол с установлением логических соединений, который обеспечивает надежную передачу упорядоченных сообщений между машинами. Поскольку процесс может иметь только единственный ожидающий выполнения запрос 9P, нет необходимости для управления потоком в IL. Подобно TCP, IL имеет адаптивные задержки: он масштабирует время подтверждения приема и время повторной передачи для соответствия сетевой скорости. Это позволяет протоколу хорошо работать как в сети Internet, так и в локальных сетях Ethernet. Также IL не делает никаких слепых повторных передач, чтобы избежать увеличения перегрузки занятых сетей. Подробное изложение можно найти в другой статье [PrWi95].
В Plan 9 реализация IL меньше и быстрее чем TCP. IL является нашим основной протокол транспорта Internet.
Обзор аутентификации
Аутентификация устанавливает личность пользователя, получающего ресурс. Пользователь, запрашивающий ресурс, называется клиент, а пользователь, предоставляющий доступ к ресурсу, называется сервер. Это обычно делается при содействии сообщения attach протокола 9P. Пользователь может быть клиентом в одном случае аутентификации и сервером в другом. Серверы всегда действуют от имени некоторого пользователя, или обычного клиента или некоего административного объекта, так что аутентификация определена для осуществления пользователями, а не машинами.
Каждый пользователь Plan 9 имеет ассоциированный с ним ключ аутентификации DES [NBS77]; личность пользователя проверяется способностью кодировать и декодировать специальные сообщения – запросы. Поскольку знание ключа пользователя дает доступ к ресурсам этого пользователя, протоколы аутентификации Plan 9 никогда не передают сообщения, содержащие ключ в явном виде.
Аутентификация является двухсторонней: в конце обмена аутентификации, каждая сторона убеждена в личности другой стороны. Каждая машина начинает обмен с ключом DES в памяти. В случае CPU и файловых серверов ключ, имя пользователя, и имя домена для сервера читаются из долговременной памяти, обычно из ПЗУ. В случае терминалов, ключ является производной от пароля набранного пользователем во время загрузки. Специальная машина, известная как сервер аутентификации, хранит базу данных ключей для всех пользователей в своем административном домене и участвует в протоколах аутентификации.
Протокол аутентификации работает следующим образом: после обмена запросами, одна сторона обращается к серверу аутентификации для создания предоставляющих доступ удостоверений, закодированных секретным ключом каждой стороны и содержащих новый ключ диалога. Каждая сторона декодирует свое собственное удостоверение и использует ключ диалога для кодирования запросов к другой стороне.
Эта структура отчасти похожа на Kerberos [MBSS87], но избегает ее доверия синхронизированным часам. Также, в отличие от Kerberos, аутентификация Plan 9 поддерживает отношения "сказано для" [LABW91], которые позволяют одному пользователю авторизировать другого; так сервер CPU выполняет процессы от имени своих клиентов.
Структура аутентификации Plan 9 формирует безопасные службы, а не зависимость от брандмауэров. Поскольку брандмауэры требуют специальный код для каждой службы, проникающей за "стену", подход Plan 9 разрешает выполняться аутентификации как единой для всех служб, работающих с 9P. Например, команда cpu надежно работает через Internet.
Аутентификация внешних соединений
Обычный протокол аутентификации Plan 9 не пригоден для служб, базирующихся на тексте, таких как Telnet или FTP. В таких случаях пользователи Plan 9 аутентифицируются с помощью портативных калькуляторов DES, называемых аутентификаторами. Аутентификатор содержит ключ для пользователя, отличающийся от ключа нормальной аутентификации пользователя. Пользователь "входит" в аутентификатор, используя 4-цифровой PIN. Правильный PIN позволяет аутентификатору обмен с сервером вызовами/ответами. Поскольку правильный обмен вызовом/ответом имеет силу только один раз, и ключи никогда не пересылаются через сеть, эта процедура не поддается атакам с повторением, оставаясь совместимой с протоколами подобными Telnet и FTP.
Особые пользователи
В Plan 9 нет суперпользователя. Каждый сервер ответственен за поддержку собственной безопасности, обычно доступ разрешается только с консоли, которая защищена паролем. Например, на файловых серверах существует уникальный администрирующий пользователь adm, со специальными привилегиями, которые применяются только к командам, набранным на физической консоли сервера. Эти привилегии имеют отношение к повседневной эксплуатации сервера, такой как, например, добавление новые пользователи и конфигурирование дисков и сетей. Привилегии не включают способности модифицировать, проверять или изменять разрешения любых файлов. Если файл защищен от чтения пользователем, только этот пользователь может предоставить доступ другим.
Серверы CPU имеют пользователя с аналогичным именем, которому разрешен административный доступ к ресурсам этого сервера, таким как, например, управляющим файлам процессов пользователя. Такое разрешение необходимо, например для того, чтобы уничтожать процессы мошенников, но не расширяется за пределы этого сервера. С другой стороны, посредством ключа, хранящегося в защищенном ПЗУ, личность администрирующего пользователя доказывается сервером аутентификации. Это позволяет серверу CPU, аутентифицировать удаленных пользователей как для доступа к самому серверу, так и для работы сервера CPU в качестве прокси от его имени.
Наконец, специальный пользователь, называемый none не имеет пароля и всегда может подключиться; каждый может назваться none. none обладает ограниченными разрешениями; например, ему не позволено изучать файлы дампа, и он может прочитать только файлы с доступом на чтение для всех.
Идея с none аналогична анонимному пользователю в службе FTP. В Plan 9, гость сервера FTP сверх того заключен в пределах специального ограниченного пространства имен. Оно отключает пользователя-гостя от системных программ, таких, например, которые содержаться в /bin, но делает возможным сделать локальные файлы пригодными для гостей, явно их связывая с пространством. Ограниченное пространство имен более безопасно, чем обычная техника экспорта специального дерева каталогов; результатом является подобие клетки вокруг пользователей, не пользующихся доверием.
Команда cpu и прокси-аутентификация
Когда совершается вызов сервера CPU для пользователя, скажем Питер, подразумевается, что Питер хочет запустить процессы под его собственным руководством. Для того чтобы осуществить эту возможность, сервер CPU делает следующее при получении вызова. Сначала приемник порождает процесс, чтобы обработать вызов. Этот процесс отличается для пользователя none, чтобы избежать выдачи разрешений, если он представляет опасность. Затем он выполняет протокол аутентификации, чтобы удостовериться в том, что вызывающий пользователь действительно – Питер, и чтобы доказывать Питеру, что сама машина является надежной. Наконец, он пересоединяется со всеми соответствующими файловыми серверами, используя протокол аутентификации, чтобы идентифицировать себя как Питера. В этом случае, сервер CPU является клиентом файлового сервера и выполняет клиентскую часть обмена аутентификации от имени Питера. Сервер аутентификации даст удостоверения процесса для завершения аутентификации только в том случае, если администратором сервера CPU позволено "говорить для" Питера.
Отношения "говорю для" [LABW91] сохраняются в таблице на сервере аутентификации. Для того чтобы упростить пользователям работу, в различных доменах аутентификации, он также содержит соотношения между именами пользователя в различных областях, говоря, например, что пользователь rtm в одном домене является тем же человеком, что и пользователь rtmorris в другом.
Файловые разрешения
Одним из преимуществ создания служб как файловых систем в том, что решения проблем владения и разрешения доступа находятся естественным образом. Так же как и в UNIX, каждый файл или каталог имеет отдельные разрешения на чтение, запись, и выполнение/поиск для владельца файла, группы файла, и кого-либо еще. Идея группы необычная: любое имя пользователя является потенциальным именем группы. Группа – это просто пользователь со списком других пользователей в группе. Условлено делать различия: большинство людей имеют имена пользователя без членов группы, тогда как группы имеют длинные списки подключенных имен. Например, группа sys по традиции включает всех системных программистов, и системные файлы доступны группе sys. Рассмотрим следующие две строки базы данных пользователей, сохраняемой на сервере:
pjw:pjw: sys::pjw,ken,philw,presotto
Первая определяет пользователя pjw как обычного пользователя. Вторая определяет пользователя sys как группу и перечисляет четырех пользователей, которые являются членами этой группы. Пустое поле (разделяются двоеточиями) является местом для пользователя, которого можно назвать лидером группы. Если группа имеет лидера, этот пользователь имеет специальные права в группе, такие как, например, свобода изменения групповых прав доступа к файлам в этой группе. Если лидер не определен, каждый участник группы считается равным лидеру. В нашем примере, только pjw может добавить участников его группы, но все участники sys являются равными партнерами в этой группе.
Обычно файлы принадлежат тому пользователю, который создает их. Имя группы наследуется от каталога, содержащего новый файл. Файлы устройств обрабатываются особо: ядро может определять принадлежность и разрешения доступа к файлу, соответствующему пользователю, получающему файл.
Хорошим примером всеобщности этих предложений являются файлы процесса, которые принадлежат и защищены от чтения владельцем процесса. Если владелец разрешить кому-нибудь еще иметь доступ к памяти процесса, например, чтобы позволить автору программы отлаживать поврежденный образ, стандартная команда chmod, примененная к файлам процесса делает эту работу.
Другим необычным применением файловых разрешений является файловая система дампа, которая не только обслуживается тем же файловым сервером, что и исходные данные, но и представлена той же базой данных пользователей. Файлам в дампе, следовательно, дана идентичная защита, что и файлам в обычной файловой системе; как только файл, принадлежащий pjw, и защищенный от чтения будет помещен в файловую систему дампа он все еще принадлежит pjw и защищен от чтения. Также, поскольку файловая система дампа неизменна, файл не может быть изменен; он защищен от чтения навсегда. Недостатки в том, что если файл можно читать, но должен быть защищен от чтения, можно будет читать всегда, и в том, что имена пользователя трудно повторно использовать.
Эксплуатационные характеристики
В качестве простой меры эксплуатационных характеристик ядра Plan 9, мы сравнили время, затрачиваемое на выполнение нескольких простых операций в Plan 9 и в SGI IRIX 5.3, работающей на SGI Challenge M с 100MHz MIPS R4400 и 1-мегабайтным вторичным кешем. Тестовая программа была написана на Alef, скомпилирована тем же компилятором, и использовала идентичные аппаратные средства, так что единственные переменные – операционная система и библиотеки.
Программа тестирует время для выполнения контекстного переключения (rendezvous в Plan 9, blockproc в IRIX); тривиального системного вызова (rfork(0) и nap(0)); и легковесного ветвления (rfork(RFPROC) и
| Тест | Plan 9 | IRIX |
|---|---|---|
| Контекстное переключение | 39 мс | 150 мс |
| Системный вызов | 6 мс | 36 мс |
| Легкое ветвление | 1300 мс | 2200 мс |
| Задержка канала | 110 мс | 200 мс |
| Полоса пропускания канала | 11678 кБ/с |
14545 кБ/с |
Хотя время, показанное Plan 9, не грандиозно, оно показывает, что ядро конкурентоспособно с коммерческими системами.
Обсуждение
В Plan 9 относительно традиционное ядро; новизна системы лежит в частях, находящихся за пределами ядра, и способе их взаимодействия. При создании Plan 9, мы продумывали все аспекты системы вместе, подбирая наилучшее решение проблем. Иногда решение охватывало множество компонентов. Примером является проблема разнородной архитектуры команд, адресуемых компиляторами (различные символы кода, переносимый объектный код), средой ($cputype и $objtype), пространством имен (связь в /bin) и другими компонентами. Иногда множество вопросов могло быть решено в одном месте. Наилучший пример – 9P, который централизует присваивание имен, доступ и аутентификацию. 9P – реальная сердцевина системы; честно говоря, ядро Plan 9 в первую очередь является мультиплексором 9P.
Фокусировка Plan 9 на файлах и присваивании имен является основой для своей выразительности. Особенно в распределенной обработке, способ присваивания имен имеет глубокое влияние на систему [Nee89]. Комбинация локальных пространств имен и глобальных соглашений соединения сетевых ресурсов помогает избежать трудностей с поддержкой глобального единого пространства имен, тогда как присваивание имен всему как файлам помогает с легкостью понимать систему, даже для новичков. Рассмотрим файловую систему дампа, которая тривиальна для использования каждым, кто знаком с иерархическими файловыми системами. На более глубоком уровне, формирование всех ресурсов над единым однородным интерфейсом облегчает взаимодействие сетей. Как только ресурс экспортирует интерфейс 9P, он прозрачно комбинируется с любой другой частью системы для построения необычных приложений; детали скрыты. Это может показаться объектно-ориентированным, но существуют различия. Прежде всего, 9P определяет фиксированный набор "методов"; он является нерасширяемым протоколом. Более важно то, что файлы являются четко определяемыми и хорошо понимаемыми и появляются снабженными знакомыми методами доступа, защиты, присваивания имен, и организацией сети. Объекты, несмотря на их общность, не появляются с этими определенными атрибутами. Уменьшая "объект" до "файла", Plan 9 получает некоторую технологию бесплатно.
Тем не менее, возможно проталкивание идеи обработки, базирующейся на файлах слишком далеко. Преобразование каждого ресурса системы в файловую систему – тип метафоры, и возможно злоупотребление метафорами. Хороший пример ограничения – /proc, который является только видом процесса, а не представлением. Для того чтобы запустить процесс, все еще необходимы обычные вызовы fork и exec, а не что-нибудь подобное
Проблема с такими примерами в том, что они требуют сервер для выполнения чего-либо не под своим управлением. Способность присваивать значение командам подобным этой не подразумевает, что значение выпадет, как следовало ожидать, из структуры ответов на запросы 9P, генерируемые им. В качестве связанного примера Plan 9 не помещает сетевые имена машин в файловое пространство имен. Сетевые интерфейсы обеспечивают очень отличающиеся модели присваивания имен, потому что использование open, create, read, и write для таких файлов не предлагает подходящего места, для кодирования всех деталей вызова установок для произвольной сети. Это не означает, что сетевой интерфейс не может быть файлоподобным, просто он должен иметь более плотно определенную структуру.
Что мы сделаем иначе в следующий раз? Некоторые неудовлетворительные элементы реализации. Использование потоков для осуществления сетевых интерфейсов в ядре позволит протоколам подключаться друг к другу динамически, например, подключить один и тот же драйвер TTY к TCP, URP, и соединениям IL, но в Plan 9 не используется эта способность к изменению конфигурации. (Это было использовано, тем не менее, в исследовательской системе UNIX, для которой потоки и были изобретены). Замена потоков статическими очередями ввода/вывода должно упростить код и сделать его быстрее.
Хотя основное ядро Plan 9 переносимо на многие машины, файловый сервер осуществляется отдельно. Это вызывает несколько проблем: драйверы, которые должны быть написаны дважды, дефекты, которые должны быть исправлены дважды, и меньшая мобильность файлового системного кода. Решение просто: ядро файлового сервера должно поддерживаться как вариант обычной операционной системы без процессов пользователя и специальных скомпилированных в ядро процессов для осуществления обслуживания файлов. Другим улучшением файловой системы будет изменение внутренней структуры. Дисководы WORM – наименее надежная часть аппаратных средств, но поскольку они хранят метаданные файловой системы, они должны присутствовать для того, чтобы обслуживать файлы. Система может быть перестроена, так что WORM будет являться только резервным устройством, с истинной файловой системой, располагающейся на магнитных дисках. Это не должно потребовать никаких изменений во внешнем интерфейсе.
Хотя Plan 9 имеет пространства имен для каждого процесса, у него нет механизма передачи описания пространства имен процесса другому процессу кроме как прямым наследованием. Команда cpu, например, не может вообще воспроизвести пространство имен терминала; он может только переинтерпретировать профиль входа пользователя и сделать подстановку для вещей, подобных имени каталога исполняемых файлов. Такой образ действий пропускает любые локальные модификации, сделанные до запуска cpu. Вместо этого должна быть возможность захвата пространства имен терминала передачи его описания удаленному процессу.
Несмотря на эти проблемы, Plan 9 работает хорошо. Он созрел в систему, которая поддерживает наши исследования, а не стал сам предметом исследования. Экспериментальная новая работа включает разработку интерфейсов для более быстрых сетей, кеширования файлов в ядре клиента, изолирование и экспорт пространств имен и способность восстанавливать состояние клиента после аварии сервера. Внимание теперь фокусируется на использовании системы для создания распределенные приложения.
Одна из причин успеха Plan 9 – то, что мы используем его для нашей повседневной работы, а не только как исследовательское средство. Активное использование заставляет нас обращаться к недостаткам по мере их возникновения и приспосабливать систему для решения своих проблем. Пройдя сквозь этот процесс, Plan 9 стал комфортабельной, продуктивной средой программирования, а также средством для дальнейшего исследования систем.
Ссылки
[9man]
Plan 9 Programmer's Manual, Volume 1, AT&T Bell Laboratories, Murray Hill, NJ, 1995.
[ANSIC]
American National Standard for Information Systems – Programming Language C, American National Standards Institute, Inc., New York, 1990.
[Duff90]
Tom Duff, "Rc – A Shell for Plan 9 and UNIX systems", Proc. of the Summer 1990 UKUUG Conf., London, July, 1990, pp. 21-33, reprinted, in a different form, in this volume.
[Fra80]
A.G. Fraser, "Datakit – A Modular Network for Synchronous and Asynchronous Traffic", Proc. Int. Conf. on Commun., June 1980, Boston, MA.
[FSSUTF]
File System Safe UCS Transformation Format (FSS-UTF), X/Open Preliminary Specification, 1993. ISO designation is ISO/IEC JTC1/SC2/WG2 N 1036, dated 1994-08-01.
[ISO10646]
ISO/IEC DIS 10646-1:1993 Information technology – Universal Multiple-Octet Coded Character Set (UCS) Part 1: Architecture and Basic Multilingual Plane.
[Kill84]
T.J. Killian, "Processes as Files", USENIX Summer 1984 Conf. Proc., June 1984, Salt Lake City, UT.
[LABW91]
Butler Lampson, Martin Abadi, Michael Burrows, and Edward Wobber, "Authentication in Distributed Systems: Theory and Practice", Proc. 13th ACM Symp. on Op. Sys. Princ., Asilomar, 1991, pp. 165-182.
[MBSS87]
S.P. Miller, B.C. Neumann, J.I. Schiller, and J.H. Saltzer, "Kerberos Authentication and Authorization System", Massachusetts Institute of Technology, 1987.
[NBS77]
National Bureau of Standards (U. S.), Federal Information Processing Standard 46, National Technical Information Service, Springfield, VA, 1977.
[Nee89]
R. Needham, "Names", in Distributed systems, S. Mullender, ed., Addison Wesley, 1989
[NeHe82]
R.M. Needham and A.J. Herbert, The Cambridge Distributed Computing System, Addison-Wesley, London, 1982
[Neu92]
B. Clifford Neuman, "The Prospero File System", USENIX File Systems Workshop Proc., Ann Arbor, 1992, pp. 13-28.
[OCDNW88]
John Ousterhout, Andrew Cherenson, Fred Douglis, Mike Nelson, and Brent Welch, "The Sprite Network Operating System", IEEE Computer, 21(2), 23-38, Feb. 1988.
[Pike87]
Rob Pike, "The Text Editor sam", Software – Practice and Experience, Nov 1987, 17(11), pp. 813-845; reprinted in this volume.
[Pike91]
Rob Pike, "8½, the Plan 9 Window System", USENIX Summer Conf. Proc., Nashville, June, 1991, pp. 257-265, reprinted in this volume.
[Pike93]
Rob Pike and Ken Thompson, "Hello World or? ALPHA?? MU?? ALPHA??? MUEPSILON or???????", USENIX Winter Conf. Proc., San Diego, 1993, pp. 43-50, reprinted in this volume.
[Pike94]
Rob Pike, "Acme: A User Interface for Programmers", USENIX Proc. of the Winter 1994 Conf., San Francisco, CA,
[Pike95]
Rob Pike, "How to Use the Plan 9 C Compiler", Plan 9 Programmer's Manual, Volume 2, AT&T Bell Laboratories, Murray Hill, NJ, 1995.
[POSIX]
Information Technology Portable Operating System Interface (POSIX) Part 1: System Application Program Interface (API) [C Language], IEEE, New York, 1990.
[PPTTW93]
Rob Pike, Dave Presotto, Ken Thompson, Howard Trickey, and Phil Winterbottom, "The Use of Name Spaces in Plan 9", Op. Sys. Rev., Vol. 27, No. 2, April 1993, pp. 72-76, reprinted in this volume.
[Presotto]
Dave Presotto, "Multiprocessor Streams for Plan 9", UKUUG Summer 1990 Conf. Proc., July 1990, pp. 11-19.
[PrWi93]
Dave Presotto and Phil Winterbottom, "The Organization of Networks in Plan 9", USENIX Proc. of the Winter 1993 Conf., San Diego, CA, pp. 43-50, reprinted in this volume.
[PrWi95]
Dave Presotto and Phil Winterbottom, "The IL Protocol", Plan 9 Programmer's Manual, Volume 2, AT&T Bell Laboratories, Murray Hill, NJ, 1995.
[RFC768]
J. Postel, RFC768, User Datagram Protocol, DARPA Internet Program Protocol Specification, August 1980.
[RFC793]
RFC793, Transmission Control Protocol, DARPA Internet Program Protocol Specification, September 1981.
[Rao91]
Herman Chung-Hwa Rao, The Jade File System, (Ph. D. Dissertation), Dept. of Comp. Sci, University of Arizona, TR 91-18.
[Rit84]
D.M. Ritchie, "A Stream Input-Output System", AT&T Bell Laboratories Technical Journal, 63(8), October, 1984.
[Tric95]
Howard Trickey, "APE The ANSI/POSIX Environment", Plan 9 Programmer's Manual, Volume 2, AT&T Bell Laboratories, Murray Hill, NJ, 1995.
[Unicode]
The Unicode Standard, Worldwide Character Encoding, Version 1.0, Volume 1, The Unicode Consortium, Addison Wesley, New York, 1991.
[UNIX85]
UNIX Time-Sharing System Programmer's Manual, Research Version, Eighth Edition, Volume 1. AT&T Bell Laboratories, Murray Hill, NJ, 1985.
[Welc94]
Brent Welch, "A Comparison of Three Distributed File System Architectures: Vnode, Sprite, and Plan 9", Computing Systems, 7(2), pp. 175-199, Spring, 1994.
[Wint95]
Phil Winterbottom, "Alef Language Reference Manual", Plan 9 Programmer's Manual, Volume 2, AT&T Bell Laboratories, Murray Hill, NJ, 1995.
Copyright © 2001 Lucent Technologies Inc. All rights reserved.
Копирайт © Перевод. Ларин Сергей, 2003